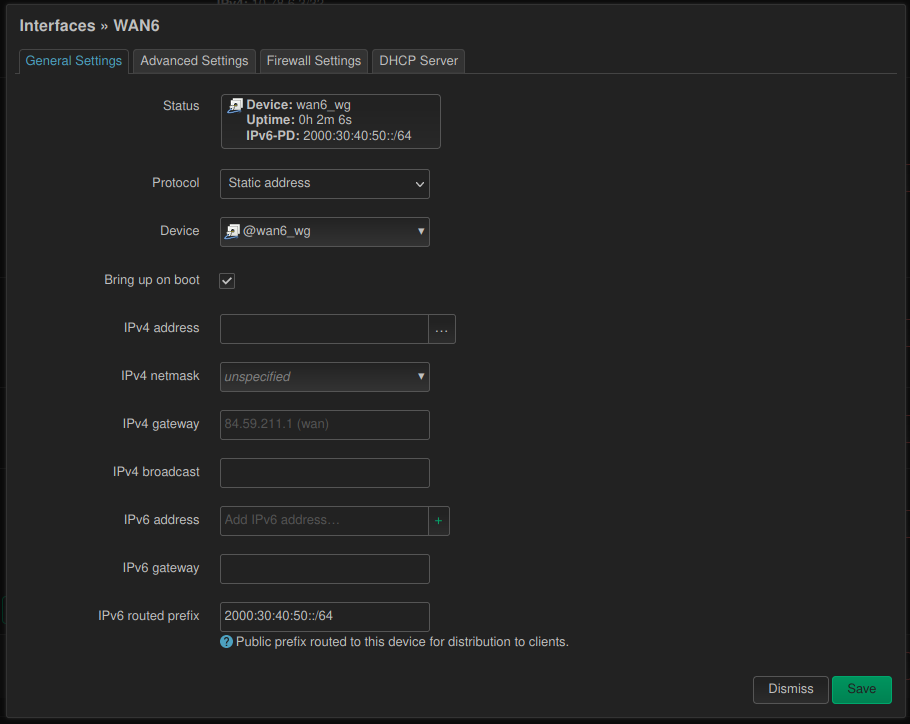
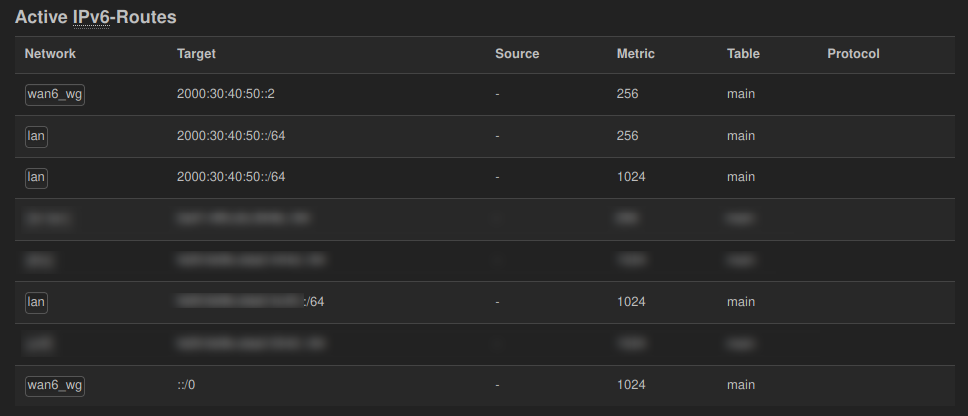
I had a weird problem. I was using network prefix translation (NPT) for routing IPv6 packets to the Internet through a VPN. But while all devices could connect to the IPv6 Internet without problems, they never did so on their own. They always preferred IPv4 connections when they had the choice. 🤨
Problem Background
I knew that modern network stacks are configured to prefer IPv6 over IPv4 generally, but was baffled why it wouldn’t use IPv6 since it was clear that connections to the Internet work. A little bit of tinkering revealed that IPv4 connections to the Internet are preferred only when my device had no global IPv6 addresses. Because I was relying on NPT my devices only had ULAs.
It turns out that the wise people making standards decided that when a device has only private IPv4 addresses and ULAs IPv4 connections are preferred for the Internet under the assumption that private IPv4 addresses are definitely NATed while IPv6’s ULA probably (definitely?) won’t. 😯
Finding a Solution
A quick search for anything related to IPv4 vs. IPv6 priority leads exclusively to questions and posts where the authors want to always have IPv4 prioritized over IPv6. Although my case was the opposite one thing became clear: it had to do with modifying /etc/gai.conf. It’s a file for configuring RFC 6724 (i.e. Default Address Selection for Internet Protocol Version 6 (IPv6)).
This allowed me to influence the selection algorithm which seemed to be needed for solving my problem. If you open this file it even has commented-out lines for solving the “always prefer IPv4 over IPv6” problem. The inverse case was not so simple, because among the precedence rules there was no address range for ULAs and adding one for my specific ULA didn’t solve the problem either:
[...]
# precedence <mask> <value>
# Add another rule to the RFC 3484 precedence table. See section 2.1
# and 10.3 in RFC 3484. The default is:
#
precedence ::1/128 50
precedence ::/0 40
precedence 2002::/16 30
precedence ::/96 20
precedence ::ffff:0:0/96 10
precedence 3fff:01:23::/48 45 # <-- added my ULA, but didn't help
#
# For sites which prefer IPv4 connections change the last line to
#
#precedence ::ffff:0:0/96 100
[...]
Manual Algorithm
I tried to take a step back and find out if a precedence setting was even the right change. I bit the bullet and tried to evaluated the “Source Address Selection” algorithm from RFC 6725 (Section 5) by hand.
Candidate Addresses
My candidate addresses for the destination (this server) were:
2a01:4f8:c2c:8101::1 # native IPv6
::ffff:116.203.176.52 # native IPv4 (mapped to IPv6 for this algorithm)
My candidate source addresses (from my WLAN connection) looked like:
3fff:01:23::aa # global dynamic noprefixroute
3fff:01:23::bb # global temporary dynamic
3fff:01:23::cc # global mngtmpaddr noprefixroute
::ffff:10.0.0.50 # private IPv4 (mapped to IPv6 for this algorithm)
The Rules
Rule 1: Prefer same address.
skip, source and destination are not the same.
Rule 2: Prefer appropriate scope.
skip, connection is unicast, so no multicast.
Rule 3: Avoid deprecated addresses.
skip, no deprecated source addresses used.
Rule 4: Prefer home addresses.
skip? I was not sure what a “home address” is supposed to be, but it seems related to mobile networks. I just assumed all source addresses were “home” addresses.
Rule 5: Prefer outgoing interface.
skip, I was already only considering the outgoing interface here.
Rule 5.5: Prefer addresses in a prefix advertised by the next-hop.
skip? all next-hops were fe00::<router's EUI64>.
Rule 6: Prefer matching label.
We get the default labels from /etc/gai.conf (mine from Ubuntu 21.10):
[…]
#label ::1/128 0 # loopback address
#label ::/0 1 # IPv6, unless matched by other rules
#label 2002::/16 2 # 6to4 tunnels
#label ::/96 3 # IPv4-compatible addresses (deprecated)
#label ::ffff:0:0/96 4 # IPv4-mapped addresses
#label fec0::/10 5 # site-local addresses (deprecated)
#label fc00::/7 6 # ULAs
#label 2001:0::/32 7 # Teredo tunnels
[…]
Then the destination addresses would get labeled like this:
2a01:4f8:c2c:8101::1 # label 1
::ffff:116.203.176.52 # label 4
And the source addresses would get labeled like this:
3fff:01:23::aa # label 6
3fff:01:23::bb # label 6
3fff:01:23::cc # label 6
::ffff:10.0.0.50 # label 4
Here we see why IPv4 addresses are selected: their destination and source addresses have the same label while the IPv6 address don’t. 😔
So I could add a new label for our ULA that has the same label as the ::/0 addresses (i.e. 1 here). I didn’t change the label on the fc00::/7 line in order not to change the behavior for all ULAs, but I wanted a special rule for my specific network. So I uncommented the default label lines and added the following line:
label 3fff:01:23::/48 1 # my ULA prefix and the same label as ::/0
Reboot (may no be strictly necessary) … and lo and behold it worked! 😎
Conclusion
While this worked I really felt uneasy messing with the address priorization especially if you take into account that I’d have to do this on every device. This is on top of the already esoteric setup for using NPT. 🙈
I later found out that when the VPN goes down (i.e. there’s no IPv6 Internet connectivity) it won’t (actually can’t) fall back to IPv4 for the Internet connection. 😓
Update 2025-12-14: Use 3fff::/20 as documentation prefix.